AMIE gains vision: A research AI agent for multimodal diagnostic dialogue
AMIE 获得愿景:用于多模态诊断对话的研究型人工智能代理
May 1, 2025
Khaled Saab, Research Scientist, Google DeepMind, and Jan Freyberg, Software Engineer, Google Research
2025 年 5 月 1 日 Khaled Saab,谷歌 DeepMind 研究科学家;Jan Freyberg,谷歌研究院软件工程师We share a first of its kind demonstration of a multimodal conversational diagnostic AI agent, multimodal AMIE.
我们将与大家分享首次展示的多模态对话诊断人工智能代理--多模态 AMIE。
Quick links
Language model–based AI systems such as Articulate Medical Intelligence Explorer (AMIE, our research diagnostic conversational AI agent recently published in Nature) have shown considerable promise for conducting text-based medical diagnostic conversations but the critical aspect of how they can integrate multimodal data during these dialogues remains unexplored. Instant messaging platforms are a popular tool for communication that allow static multimodal information (e.g., images and documents) to enrich discussions, and their adoption has also been reported in medical settings. This ability to discuss multimodal information is particularly relevant in medicine where investigations and tests are essential for effective care and can significantly inform the course of a consultation. Whether LLMs can conduct diagnostic clinical conversations that incorporate this more complex type of information is therefore an important area for research.
基于语言模型的人工智能系统,如 Articulate Medical Intelligence Explorer(AMIE,我们最近在《自然》杂志上发表的诊断对话式人工智能代理研究成果),在进行基于文本的医疗诊断对话方面已显示出相当大的前景,但它们如何在这些对话中整合多模态数据这一关键问题仍有待探索。即时信息平台是一种流行的交流工具,它允许用静态多模态信息(如图像和文档)来丰富讨论内容,在医疗环境中也有采用即时信息平台的报道。这种讨论多模态信息的能力在医学领域尤为重要,因为调查和测试对有效护理至关重要,并能为会诊过程提供重要信息。因此,法学硕士能否在进行诊断性临床对话时纳入这种更为复杂的信息,是一个重要的研究领域。
In our new work, we advance AMIE with the ability to intelligently request, interpret, and reason about visual medical information in a clinical conversation, working towards accurate diagnosis and management plans. To this end, building on multimodal Gemini 2.0 Flash as the core component, we developed an agentic system that optimizes its responses based on the phase of the conversation and its evolving uncertainty regarding the underlying diagnosis. This combination resulted in a history-taking process that better emulated the structure of history-taking that is common in real-world clinical practice.
在我们的新工作中,我们推进了 AMIE 的发展,使其能够在临床对话中智能地请求、解释和推理视觉医疗信息,从而实现准确的诊断和管理计划。为此,我们以多模态双子座 2.0 Flash 为核心组件,开发了一个代理系统,该系统可根据对话的阶段及其对基本诊断不断变化的不确定性优化其响应。这种组合使病史采集过程更好地模拟了现实世界临床实践中常见的病史采集结构。
Through an expert evaluation adapting Objective Structured Clinical Examinations (OSCEs), a standardized assessment used globally in medical education, we compared AMIE’s performance to primary care physicians (PCPs) and evaluated its behaviors on a number of multimodal patient scenarios. Going further, preliminary experiments with Gemini 2.5 Flash indicate the possibility of improving AMIE more so by integrating the latest base model.
客观结构化临床检查(OSCE)是全球医学教育中使用的标准化评估方法,通过专家评估,我们将 AMIE 的表现与初级保健医生(PCPs)进行了比较,并评估了其在一些多模态患者场景中的行为。此外,Gemini 2.5 Flash 的初步实验表明,通过整合最新的基础模型,AMIE 有可能得到进一步改进。
We introduce multimodal AMIE: our diagnostic conversational AI that can intelligently request, interpret and reason about visual medical information during a clinical diagnostic conversation. We integrate multimodal perception and reasoning into AMIE through the combination of natively multimodal Gemini models and our state-aware reasoning framework.
我们介绍了多模态 AMIE:我们的诊断对话式人工智能,可以在临床诊断对话中智能地请求、解释和推理视觉医疗信息。我们通过结合本地多模态双子座模型和我们的状态感知推理框架,将多模态感知和推理整合到 AMIE 中。
Advancing AMIE for multimodal reasoning
推进多模式推理的 AMIE
We introduce two key advances to AMIE. First, we developed a multimodal, state-aware reasoning framework. This allows AMIE to adapt its responses based on its internal state, which captures its knowledge about the patient at a given point in the conversation, and to gather information efficiently and effectively to derive appropriate diagnoses (e.g., requesting multimodal information, such as skin photos, to resolve any gaps in its knowledge). Second, to inform key design choices in the AMIE system, we created a simulation environment for dialogue evaluation in which AMIE converses with simulated patients based on multimodal scenarios grounded in real-world datasets, such as the SCIN dataset of dermatology images.
我们为 AMIE 引入了两个关键进展。首先,我们开发了一个多模态、状态感知的推理框架。这使 AMIE 能够根据其内部状态(即在对话中的特定时刻对患者的了解)调整其响应,并高效地收集信息,以得出适当的诊断结果(例如,请求皮肤照片等多模态信息,以解决其知识中的任何空白)。其次,为了为 AMIE 系统的关键设计选择提供信息,我们创建了一个用于对话评估的模拟环境,在该环境中,AMIE 根据真实世界数据集(如 SCIN 皮肤科图像数据集)中的多模态场景与模拟病人进行对话。
Emulating history taking of experienced clinicians: State-aware reasoning
模仿经验丰富的临床医生采集病史状态感知推理
Real clinical diagnostic dialogues follow a structured yet flexible path. Clinicians methodically gather information as they form potential diagnoses. They can strategically request and interpret further details from a wide variety of multimodal data (for example, skin photos, lab results or ECG measurements). In light of such new evidence, they can ask appropriate clarification questions to resolve information gaps and delineate diagnostic possibilities.
真正的临床诊断对话遵循结构化但灵活的路径。临床医生在形成潜在诊断时会有条不紊地收集信息。他们可以从各种多模态数据(如皮肤照片、化验结果或心电图测量结果)中有策略地要求和解释更多细节。根据这些新的证据,他们可以提出适当的澄清问题,以解决信息缺口并确定诊断的可能性。
To equip AMIE with a similar dialogue capability, we introduce a novel state-aware phase transition framework that orchestrates the conversation flow. Leveraging Gemini 2.0 Flash, this framework dynamically adapts AMIE's responses based on intermediate model outputs that reflect the evolving patient state, diagnostic hypotheses, and uncertainty. This enables AMIE to request relevant multimodal artifacts when needed, interpret their findings accurately, integrate this information seamlessly into the ongoing dialogue, and use it to refine diagnoses and guide further questioning. This emulates the structured, adaptive reasoning process used by experienced clinicians.
为了让 AMIE 具备类似的对话能力,我们引入了一个新颖的状态感知阶段转换框架,用于协调对话流程。利用 Gemini 2.0 Flash,该框架可根据中间模型输出动态调整 AMIE 的响应,这些输出反映了不断变化的患者状态、诊断假设和不确定性。这使 AMIE 能够在需要时请求相关的多模态人工制品,准确解释其发现,将这些信息无缝集成到正在进行的对话中,并用于完善诊断和指导进一步提问。这模仿了经验丰富的临床医生所使用的结构化、适应性推理过程。
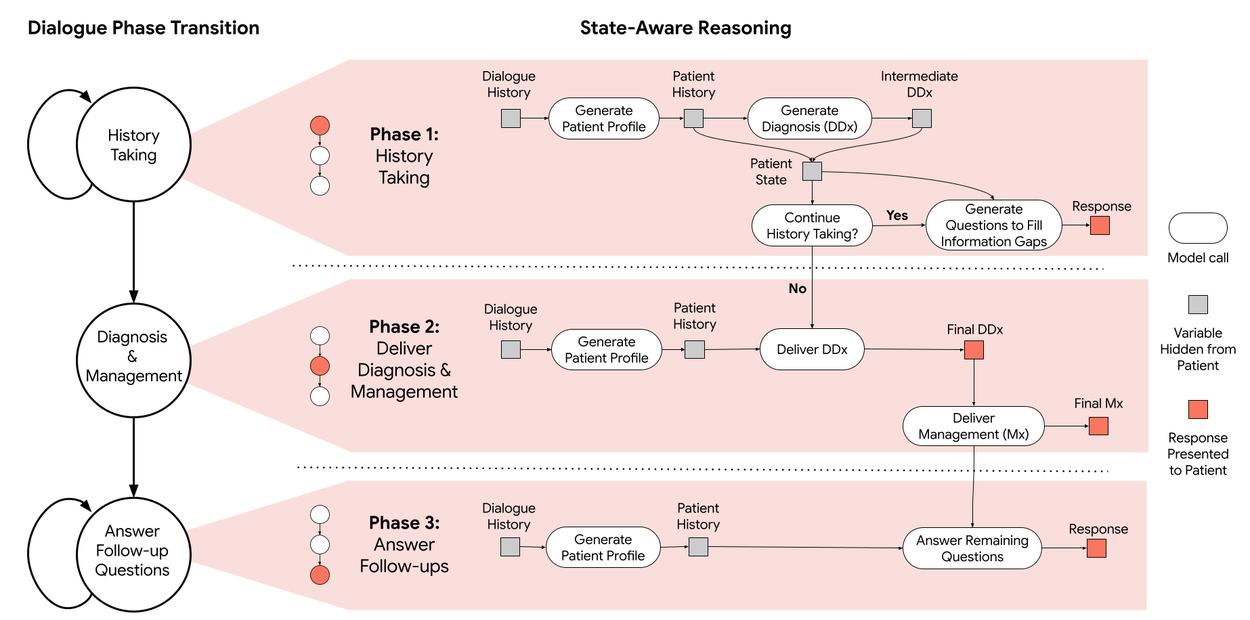
AMIE employs a state-aware dialogue framework that progresses through three distinct phases, each with a clear objective: History Taking, Diagnosis & Management, and Follow-up. AMIE's dynamic internal state — reflecting its evolving understanding of the patient, diagnoses, and knowledge gaps — drives its actions within each phase (e.g., information gathering and providing explanations to the patient). Transitions between phases are triggered when the system assesses that the objectives of the current phase have been met.
AMIE 采用了一种状态感知对话框架,通过三个不同的阶段进行对话,每个阶段都有明确的目标:病史采集、诊断与管理以及随访。AMIE 的动态内部状态反映了其对病人、诊断和知识差距的不断发展的理解,并驱动其在每个阶段的行动(例如,收集信息和向病人提供解释)。当系统评估当前阶段的目标已经实现时,就会触发阶段之间的转换。
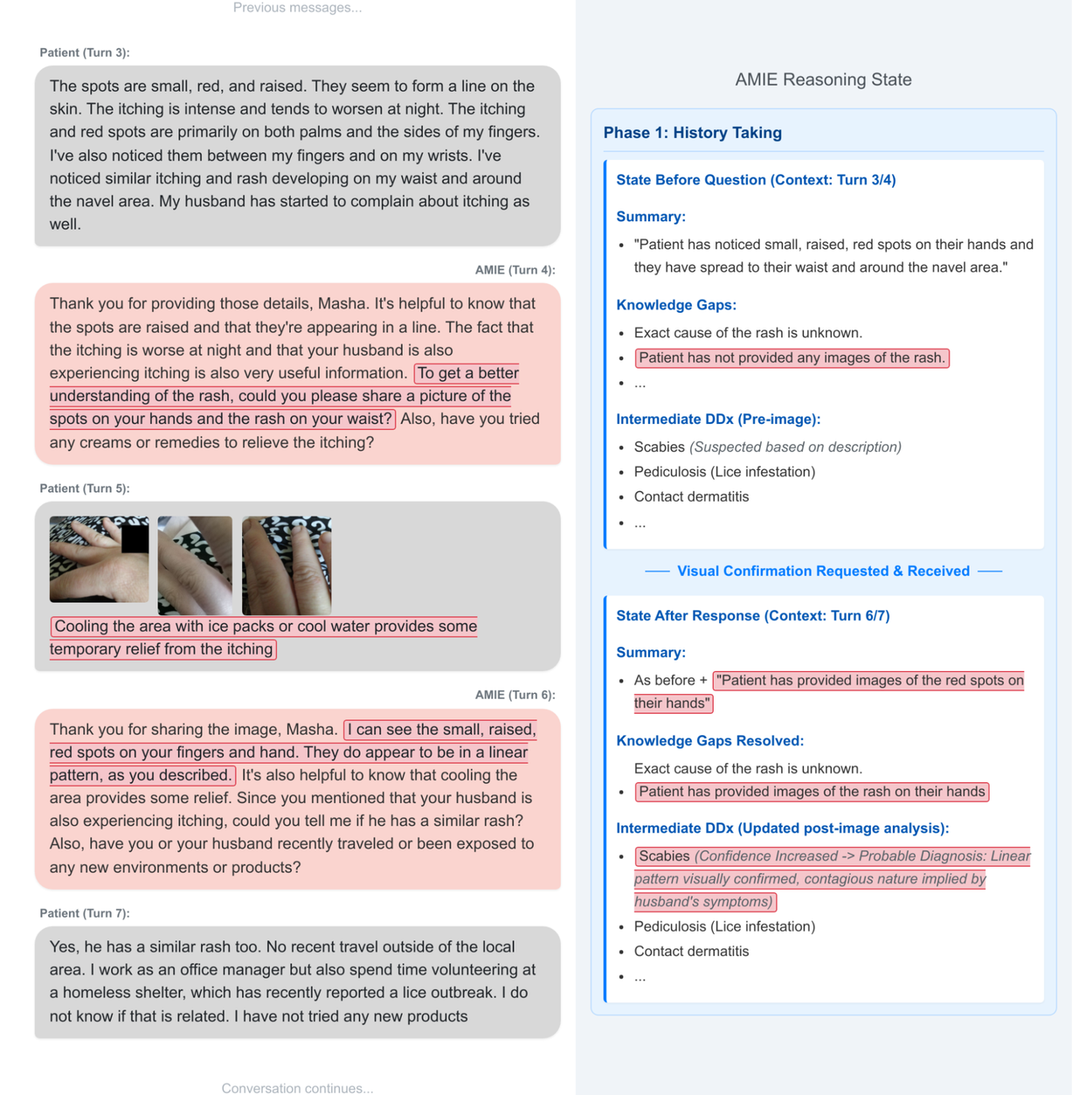
An example of state-aware reasoning in practice during a simulated consultation with a patient-actor. At the start of this part of the interaction, AMIE is aware of the gaps in its knowledge about the case: the lack of images. AMIE requests these images, and once provided, updates its knowledge as well as its differential diagnosis.
在与病人演员的模拟问诊过程中,状态感知推理在实践中的一个例子。在这部分互动开始时,AMIE 意识到自己对病例知识的不足:缺乏图像。AMIE 请求获得这些图像,一旦获得,就会更新其知识和鉴别诊断。
Accelerating development: A robust simulation environment
加速开发:强大的模拟环境
To enable rapid iteration and robust automated assessment, we developed a comprehensive simulation framework:
为了实现快速迭代和稳健的自动评估,我们开发了一个综合模拟框架:
- We generate realistic patient scenarios, including detailed profiles and multimodal artifacts derived from datasets like PTB-XL and SCIN, augmented with plausible clinical context using Gemini models with web search.
我们从 PTB-XL 和 SCIN 等数据集中生成逼真的患者场景,包括详细的特征和多模态伪影,并利用双子座模型和网络搜索增强了可信的临床背景。 - Then, we simulate turn-by-turn multimodal dialogues between AMIE and a patient agent adhering to the scenario.
然后,我们模拟了 AMIE 与患者代理之间的多模态回合对话。 - Lastly, we evaluate these simulated dialogues, using an auto-rater agent, against predefined clinical criteria such as diagnostic accuracy, information gathering effectiveness, management plan appropriateness, and safety (e.g., hallucination detection).
最后,我们使用自动评分器代理,根据预定义的临床标准(如诊断准确性、信息收集有效性、管理计划适当性和安全性(如幻觉检测))对这些模拟对话进行评估。
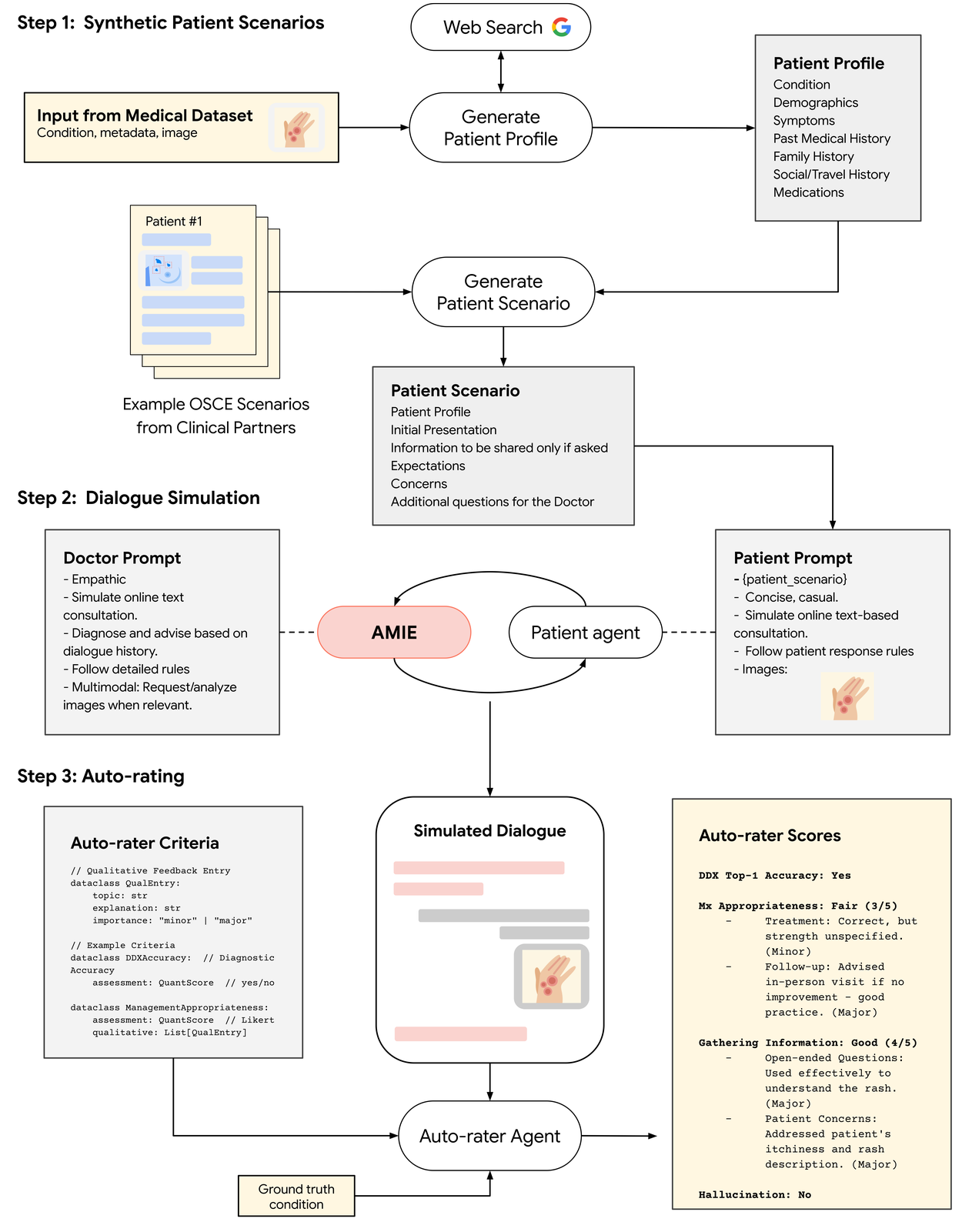
Overview of our simulation environment for multimodal dialogue evaluation.
多模态对话评估模拟环境概述。
Expert evaluation: The multimodal virtual OSCE study
专家评估:多模式虚拟 OSCE 研究
To evaluate multimodal AMIE, we carried out a remote expert study with 105 case scenarios where validated patient actors engaged in conversations with AMIE or primary care physicians (PCPs) in the style of an OSCE study. The sessions were performed through a chat interface where patient actors could upload multimodal artifacts (e.g., skin photos), mimicking the functionality of multimedia instant messaging platforms. We introduced a framework for evaluating multimodal capability in the context of diagnostic dialogues, along with other clinically meaningful metrics, such as history-taking, diagnostic accuracy, management reasoning, communication skills, and empathy.
为了评估多模态 AMIE,我们开展了一项远程专家研究,在 105 个案例场景中,经过验证的患者演员以 OSCE 研究的方式与 AMIE 或初级保健医生(PCP)进行了对话。对话通过聊天界面进行,患者可上传多模态人工制品(如皮肤照片),模仿多媒体即时通讯平台的功能。我们引入了一个框架,用于评估诊断对话中的多模态能力以及其他有临床意义的指标,如病史采集、诊断准确性、管理推理、沟通技巧和移情能力。
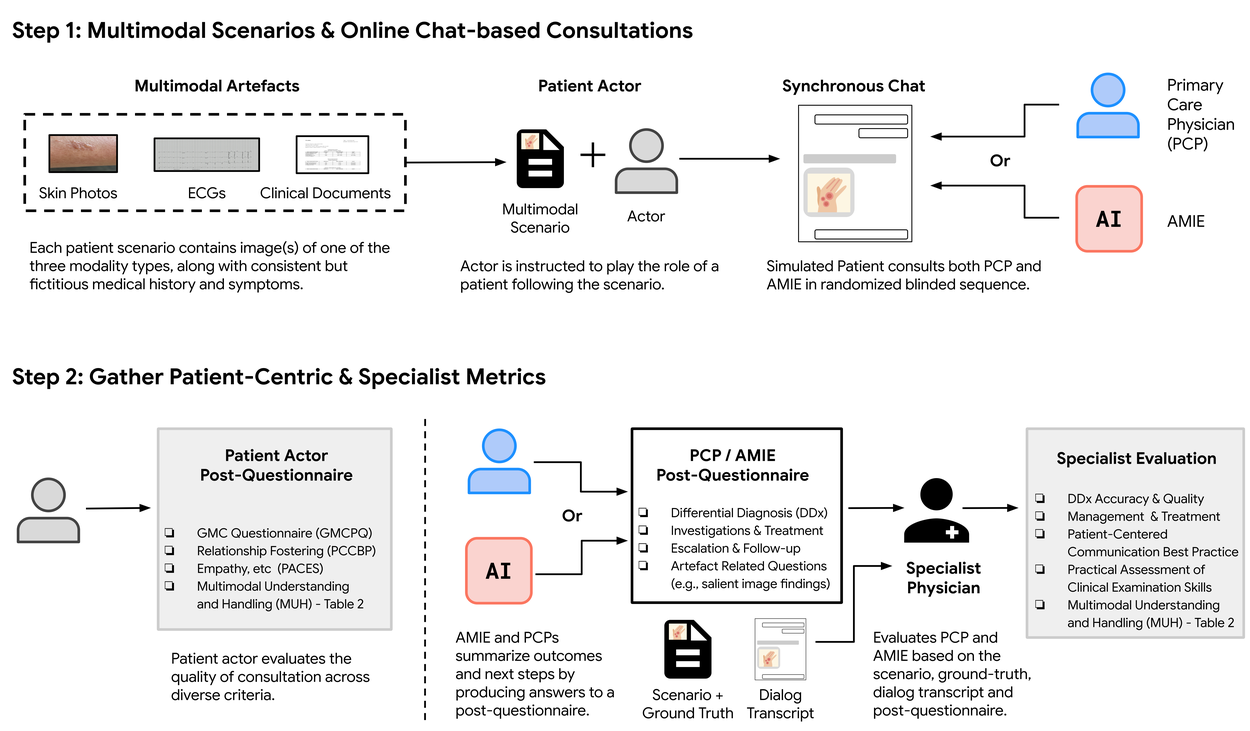
Overview of our simulation environment for multimodal dialogue evaluation.
多模态对话评估模拟环境概述。
Results: AMIE matches or exceeds PCP performance in multimodal consultations
结果:AMIE 在多模式会诊中的表现与初级保健医生不相上下,甚至有过之而无不及
Our study demonstrated that AMIE can outperform PCPs in interpreting multimodal data in simulated instant-messaging consultation. It also scored higher in other key indicators of consultation quality, such as diagnostic accuracy, management reasoning, and empathy. AMIE produced more accurate and more complete differential diagnoses than PCPs in this research setting:
我们的研究表明,在模拟即时信息会诊中,AMIE 在解释多模态数据方面优于初级保健医生。在诊断准确性、管理推理和同理心等其他关键咨询质量指标方面,AMIE 的得分也更高。在这项研究中,AMIE 比初级保健医生做出了更准确、更完整的鉴别诊断:
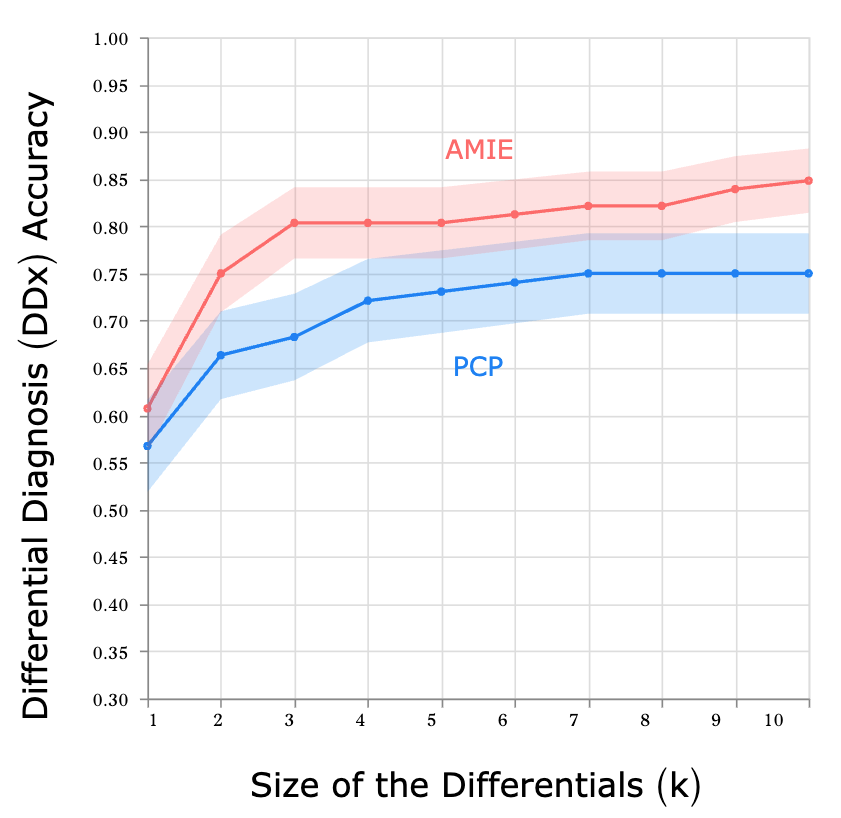
Top-k accuracy of differential diagnosis (DDx). AMIE and primary care physicians (PCPs) are compared across 105 scenarios with respect to the ground truth diagnosis. Upon conclusion of the consultation, both AMIE and PCPs submit a differential diagnosis list (at least 3, up to 10 plausible items, ordered by likelihood).
鉴别诊断(DDx)的最高准确率。在 105 种情况下,AMIE 和初级保健医生 (PCP) 就基本真实诊断进行比较。会诊结束后,AMIE 和初级保健医生都会提交一份鉴别诊断清单(至少 3 项,最多 10 项,按可能性排序)。
We asked both patient actors and specialist physicians in dermatology, cardiology, and internal medicine to rate the conversations on a number of scales. We found that AMIE was rated more highly on average in the majority of our evaluation rubrics. Notably, specialists also assigned higher scores to the quality of image interpretation and reasoning along with other key attributes of effective medical conversations, such as the completeness of differential diagnosis, the quality of management plans, and the ability to escalate (e.g., for urgent treatment) appropriately. The degree to which AMIE hallucinated (misreported) findings that are not consistent with the provided image artifacts was deemed to be statistically indistinguishable from the degree of PCP hallucinations. From the patient actors’ perspective, AMIE was often perceived to be more empathetic and trustworthy. More comprehensive findings can be found in the paper.
我们请患者和皮肤科、心脏科和内科的专科医生根据一系列量表对对话进行评分。我们发现,在大多数评估标准中,AMIE 的平均评分更高。值得注意的是,专家们对图像解读和推理的质量以及有效医疗对话的其他关键属性(如鉴别诊断的完整性、管理计划的质量以及适当升级(如紧急治疗)的能力)也给予了更高的评分。AMIE 幻觉(误报)与所提供的图像假象不一致的程度被认为在统计学上与 PCP 幻觉的程度没有区别。从患者行为者的角度来看,AMIE 通常被认为更有同情心、更值得信赖。更全面的研究结果见论文。
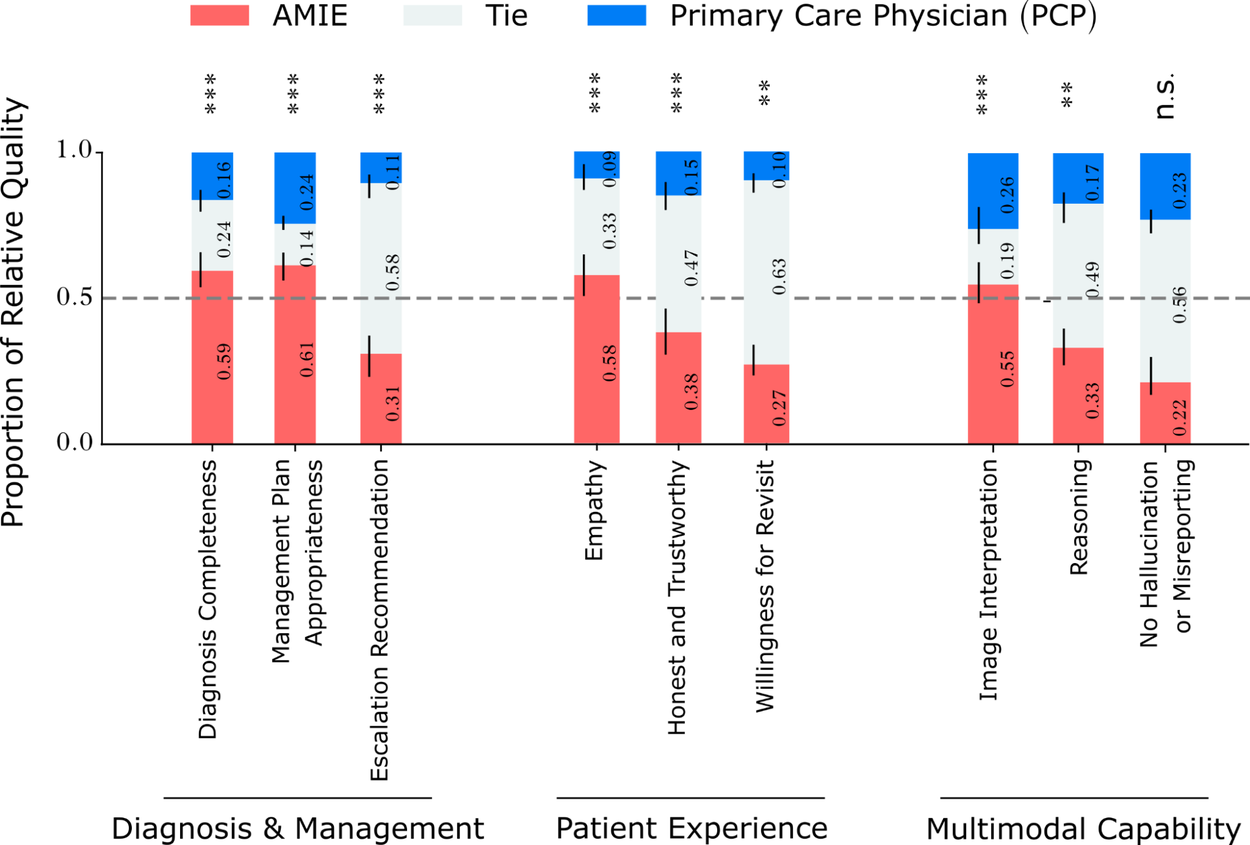
Relative performance of PCPs and AMIE on other key OSCE axes as assessed by specialist physicians and patient actors. The red segments represent the proportions of patient scenarios for which AMIE’s dialogues were rated more highly than the PCPs on the respective axes. The asterisks represent statistical significance (*: p<0.05, **: p<0.01, ***: p<0.01, n.s.: not significant)
根据专科医生和患者参与者的评估,初级保健医生和 AMIE 在其他关键 OSCE 轴上的相对表现。红色部分代表在患者情景中,AMIE 的对话在相应轴上的评分高于初级保健医生的比例。星号代表统计学意义(*: p<0.05, **: p<0.01, ***: p<0.01, n.s.: 无意义)
Evolving the base model: Preliminary results with Gemini 2.5 Flash
基础模型的演变:使用 Gemini 2.5 Flash 的初步结果
The capabilities of Gemini models are continuously advancing, so how would multimodal AMIE's performance change when leveraging a newer, generally more capable base model? To investigate this, we conducted a preliminary evaluation using our dialogue simulation framework, comparing the performance of multimodal AMIE built upon the new Gemini 2.5 Flash model against the current Gemini 2.0 Flash version rigorously validated in our main expert study.
双子座模型的功能在不断进步,那么在利用更新、功能更强的基础模型时,多模态 AMIE 的性能会发生怎样的变化?为了研究这个问题,我们使用对话模拟框架进行了初步评估,比较了建立在新的 Gemini 2.5 Flash 模型基础上的多模式 AMIE 与在主要专家研究中经过严格验证的当前 Gemini 2.0 Flash 版本的性能。
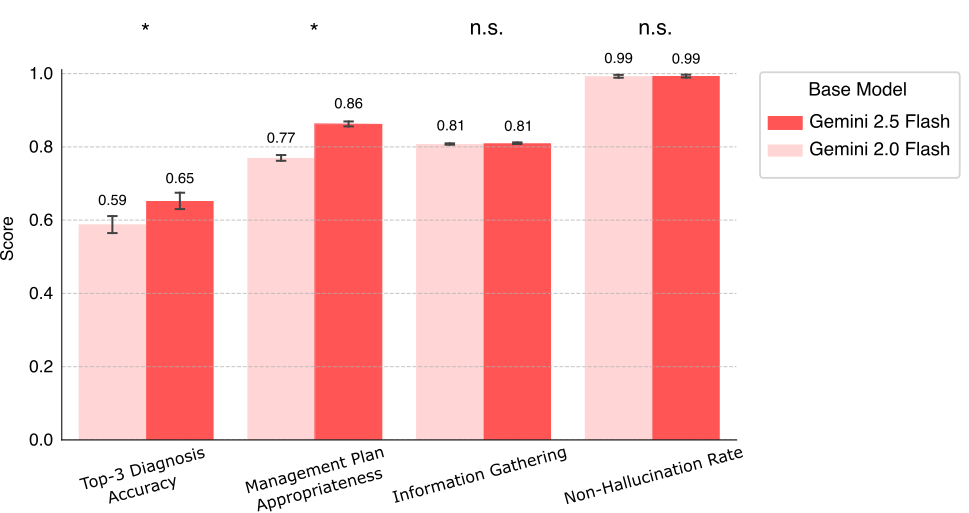
Comparison of multimodal AMIE performance using Gemini 2.0 Flash vs. Gemini 2.5 Flash as the base model, evaluated via the automated simulation framework. Scores represent performance on key clinical criteria (* indicates statistically significant difference (p < 0.05) and “n.s.” indicates non-significant difference).
使用 Gemini 2.0 Flash 与 Gemini 2.5 Flash 作为基础模型的多模式 AMIE 性能比较,通过自动模拟框架进行评估。分数代表主要临床标准的表现(*表示差异有统计学意义(P < 0.05),"n.s. "表示差异无意义)。
The results as summarized in the chart above suggest possibilities for further improvements. Notably, the AMIE variant using Gemini 2.5 Flash demonstrated statistically significant gains in Top-3 Diagnosis Accuracy (0.65 vs. 0.59) and Management Plan Appropriateness (0.86 vs. 0.77). On the other hand, performance on Information Gathering remained consistent (0.81), and Non-Hallucination Rate was maintained at its current high level (0.99). These preliminary findings suggest that future iterations of AMIE could benefit from advances in the underlying base models, potentially leading to even more accurate and helpful diagnostic conversations.
上图总结的结果表明了进一步改进的可能性。值得注意的是,使用 Gemini 2.5 Flash 的 AMIE 变体在前三名诊断准确率(0.65 对 0.59)和管理计划适当性(0.86 对 0.77)方面都有显著的统计学提高。另一方面,信息收集的成绩保持一致(0.81),非幻觉率保持在目前的高水平(0.99)。这些初步研究结果表明,AMIE 未来的迭代可能会受益于基础模型的进步,从而有可能带来更准确、更有帮助的诊断对话。
We emphasize, however, that these findings are from automated evaluations and that rigorous assessment through expert physician review is essential to confirm these performance benefits.
不过,我们要强调的是,这些结果都是自动评估的结果,要确认这些性能优势,必须通过专家医生的审查进行严格评估。
Limitations and future directions
局限性和未来方向
- Importance of real-world validation: This study explores a research-only system in an OSCE-style evaluation using patient actors, which substantially under-represents the complexity and extent of multimodal data, diseases, patient presentations, characteristics and concerns of real-world care. It also under-represents the considerable expertise of clinicians as it occurs in an unfamiliar setting without usual practice tools and conditions. It is important to interpret the research with appropriate caution and avoid overgeneralization. Continued evaluation studies and responsible development are paramount in such research towards building AI capabilities that might safely and effectively augment healthcare delivery. Further research is therefore needed before real-world translation to safely improve our understanding of the potential impacts of AMIE on clinical workflows and patient outcomes as well as to characterise and improve safety and reliability of the system under real-world constraints and challenges. As a first step towards this, we are already embarking on a prospective consented research study with Beth Israel Deaconess Medical Center that will evaluate AMIE in a real clinical setting.
真实世界验证的重要性:这项研究在使用患者行为者进行的 OSCE 式评估中探索了一个仅供研究的系统,但这远远不能反映真实世界护理中多模态数据、疾病、患者表现、特征和关注点的复杂性和广泛性。由于是在没有常规实践工具和条件的陌生环境中进行的,因此也不能充分反映临床医生的大量专业知识。重要的是,在解释研究时要适当谨慎,避免以偏概全。在此类研究中,持续的评估研究和负责任的开发是最重要的,以便建立人工智能能力,安全有效地增强医疗保健服务。因此,在实际应用之前,我们需要开展进一步的研究,以安全地提高我们对 AMIE 对临床工作流程和患者预后的潜在影响的认识,并在现实世界的限制和挑战下确定和提高系统的安全性和可靠性。作为实现这一目标的第一步,我们已经开始与贝斯以色列女执事医疗中心(Beth Israel Deaconess Medical Center)合作开展一项前瞻性研究,将在真实的临床环境中对 AMIE 进行评估。 - Real-time audio-video interaction: In telemedical practice, physicians and patients more commonly have richer real-time multimodal information with voice-based interaction over video calls. Chat-based interactions are less common and inherently limit the physician and patients’ ability to share non-verbal cues, perform visual assessments and conduct guided examinations, all of which are readily available and are often essential for providing high-quality care in remote consultations. Development and evaluation of such real-time audio-video–based interaction for AMIE remains important future work.
实时音视频互动:在远程医疗实践中,医生和患者通常通过视频通话进行语音交互,从而获得更丰富的实时多模态信息。而基于聊天的交互方式则不太常见,而且从本质上限制了医生和患者分享非语言线索、进行视觉评估和引导检查的能力,而所有这些都是随时可用的,而且往往是在远程会诊中提供高质量护理所必不可少的。为 AMIE 开发和评估这种基于音频视频的实时互动仍是未来的重要工作。 - Evolution of the AMIE system: The new multimodal capability introduced here complements other ongoing advances, such as the capability for longitudinal disease management reasoning we recently shared. These milestones chart our progress towards a unified system that continually incorporates new, rigorously evaluated capabilities important for conversational AI in healthcare.
AMIE 系统的演变:这里介绍的新多模态功能是对其他正在取得的进展的补充,例如我们最近分享的纵向疾病管理推理功能。这些里程碑描绘了我们向统一系统迈进的过程,该系统不断融入新的、经过严格评估的功能,这些功能对医疗保健领域的对话式人工智能非常重要。
Conclusion: Towards more capable and accessible AI in healthcare
结论:让人工智能在医疗保健领域发挥更大作用,让人们更容易获得人工智能服务
The integration of multimodal perception and reasoning marks a helpful step forward for capabilities of conversational AI in medicine. By enabling AMIE to "see" and interpret the kinds of visual and documentary evidence crucial to clinical practice, powered by the advanced capabilities of Gemini, this research demonstrates the AI capabilities needed to more effectively assist patients and clinicians in high-quality care. Our research underscores our commitment to responsible innovation with rigorous evaluations toward real-world applicability and safety.
多模态感知与推理的整合标志着对话式人工智能在医学领域的能力向前迈出了有益的一步。借助双子座的先进功能,AMIE 能够 "看到 "并解释对临床实践至关重要的各种视觉和文件证据,这项研究展示了更有效地协助患者和临床医生进行高质量护理所需的人工智能能力。我们的研究强调了我们对负责任的创新的承诺,并对现实世界的适用性和安全性进行了严格的评估。
Acknowledgements 致谢
The research described here is joint work across many teams at Google Research and Google DeepMind. We are grateful to all our co-authors: CJ Park, Tim Strother, Yong Cheng, Wei-Hung Weng, David Stutz, Nenad Tomasev, David G.T. Barrett, Anil Palepu, Valentin Liévin, Yash Sharma, Roma Ruparel, Abdullah Ahmed, Elahe Vedadi, Kimberly Kanada, Cìan Hughes, Yun Liu, Geoff Brown, Yang Gao, S. Sara Mahdavi, James Manyika, Katherine Chou, Yossi Matias, Kat Chou, Avinatan Hassidim, Dale R. Webster, Pushmeet Kohli, S. M. Ali Eslami, Joëlle Barral, Adam Rodman, Vivek Natarajan, Mike Schaekermann, Tao Tu, Alan Karthikesalingam, and Ryutaro Tanno.
本文所描述的研究是谷歌研究院和谷歌 DeepMind 多个团队的共同成果。我们对所有共同作者表示感谢:CJ Park、Tim Strother、Yong Cheng、Wei-Hung Weng、David Stutz、Nenad Tomasev、David G.T. Barrett、Anil Palepu、Valentin Liévin、Yash Sharma、Roma Ruparel、Abdullah Ahmed、Elahe Vedadi、Kimberly Kanada、Cìan Hughes、Yun Liu、Geoff Brown、Yang Gao、S.Sara Mahdavi、James Manyika、Katherine Chou、Yossi Matias、Kat Chou、Avinatan Hassidim、Dale R. Webster、Pushmeet Kohli、S. M. Ali Eslami、Joëlle Barral、Adam Rodman、Vivek Natarajan、Mike Schaekermann、Tao Tu、Alan Karthikesalingam 和 Ryutaro Tanno。
-
Labels: 标签
- Generative AI 生成式人工智能
-
Health & Bioscience
健康与生物科学
Quick links 快速链接
Other posts of interest
其他感兴趣的帖子
-

May 14, 2025 2025 年 5 月 14 日
Deeper insights into retrieval augmented generation: The role of sufficient context
深入了解检索增强生成:充分语境的作用-
Data Mining & Modeling
数据挖掘与建模· - Generative AI 生成式人工智能·
- Machine Intelligence 机器智能
-
Data Mining & Modeling
-
May 12, 2025 2025 年 5 月 12 日
Bringing 3D shoppable products online with generative AI
利用人工智能生成技术将 3D 可购物产品推向网络- Generative AI 生成式人工智能
-
May 7, 2025 2025 年 5 月 7 日
A new light on neural connections
神经连接的新曙光- General Science 普通科学·
- Health & Bioscience 健康与生物科学